Chapter One: An Acoustics Primer

10. What is resonance? | Page 2
Formants and Fixed Formants
Specific resonant frequency areas are called formants. The locations of formant areas in an existing sound are referred to as spectral peaks. Sometimes individual formant areas can be very narrow and selective or quite wide (a characteristic referred to as 'Q,' covered later). The fabled Helmholtz-Koenig resonators were extremely narrow, rejecting almost everything but their central resonant frequency. Unless instruments are able to change their size or shape with each note, most, such as a piano, exhibit a complex of many resonant frequencies that do not change regardless of the note played, and these immovable spectral areas are called fixed formants. When differing frequencies are applied to these fixed resonances, different numbered partials may be excited for each separate note. This is part of what gives instruments both their overall tone quality and their registral characteristics — that is, they have noticeably different tone qualities playing low pitches than playing high ones, since differing partials of their excitation source spectra are being enhanced.
Cellists are familiar with a "wolf tone," which is a particular pitch in which there are virtually no lower partials resonated due to phase cancellation between the actual pitch and a resonated artificial partial. This creates an unpleasant, stuttering "dead" result and is a normal feature of most string instruments. When purchasing or readjusting an instrument, cellists look for ones where the wolf tone falls in between equal-tempered pitches or they may use a wolf-tone eliminator, a small mass attached to the tail-piece side of the string.
Digital samplers can change pitch by simply speeding up or slowing down the replay rate of a recorded note to change its pitch—unfortunately, this also transposes the instrument's fixed formants. If we took the lowest ‘C’ Steinway grand piano sample and transposed it up 4 octaves, the result would be much more akin to a cheap honky-tonk instrument, since the true acoustic effect would be to transpose all of the fixed resonances of the Steinway, essentially miniaturizing it. "Alvin and the Chipmunks" made a living by such transpositions.

Formant Transposition
Modern-day audio editing software often gives an opportunity to shift formants independently from the transposition of the main sound, leading potentially to sonically interesting results. On the left is the Spectral Effects transposition/speed module from Mark of the Unicorn's Digital Performer digital audio workstation. Note the separate control to transpose the formants, as well as the ability to alter the time domain separately from pitch.
Vocal Formants
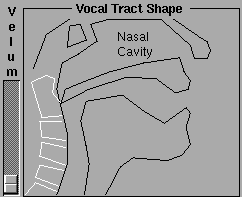
We use formants everyday—they are the vowel sounds we produce when speaking or singing. Our vocal cords are the excitation source, but they don’t change shape for each vowel. Instead, we change the shape of our oral cavity, which (along with our sinuses) creates a specific complex of resonances resulting in an ‘A’, ‘O’, ‘U’ etc. Unlike instrumental fixed formants, when we produce diphthongs (vowels that morph from one into another, such as "ai-yo" or "oo-ee"), we smoothly change the shape of our oral cavity and hence the resonating characteristics. The Internet has many charts on the resonant frequency characteristics of vowels, often by voice type, such as soprano, tenor, or language and culture, and often listing just the first several formants (F1, F2, F3...), though better if they also list their relative strengths and bandwidths, like this linked Csound manual does. Later on, when we study synthesis, we will discuss resonant filters that allow us to enhance or reduce certain specific frequency areas of a signal and make use of these characteristics.
SPASM Singing Simulation
Perry Cook (Professor Emeritus, Princeton University) created software in the late 1980's that simulated a singing voice by allowing the user to graphically morph the shape of an artificial vocal tract via control sliders and thereby shift formants into vowels, diphthongs, etc.. Recording a sequence of changes, plus the addition of a few additional speech elements allowed for the simulation of a singing voice (which he called "Sheila"). This was great fun to use, and was an example of digital waveguide synthesis mentioned on the previous page. Here is an example of Sheila singing.
Room Resonance
Rooms, or any fully or partially enclosed listening environment, such as a gym, auditorium, cave, canyon, also act as resonators when excited by an acoustic source, such as a loudspeaker or instrumental group. They resonate or amplify certain frequencies, and minimize others. These complexes of resonant frequencies are called room modes (caused primarily by standing waves), and are determined by several factors, most importantly the shape or dimensions of the room itself. Even more troublesome, the mixes of resonances change at different locations in the room and propagate in different directions, so again, we advise an electronic composer to move in all directions when monitoring to see if this is the case. In a concert hall or recording/composing studio environment, efforts are made to both avoid excess selective resonance in the first place by avoiding parallel walls, and by carefully proportioning the width, length and height of the room and by proper placement of speakers. A cube, for example, would have a triple resonance at the same frequency, since a standing wave side to side, front to back, and bottom to top would create the same resonant mode—bad. Equally as important, careful selection of room materials, and acoustic treatments (acoustically-absorbent panels, bass traps, etc.) attempt to make the listening environment as flat as possible in studios. Some materials, such as curtains, only cut very high frequencies (usually above 5k). Electronic means are further employed for audio playback in a process called equalization, with analog or digital equalizers (often graphic equalizers) set to cut overly-resonant frequencies and boost attenuated frequencies (again being aware that the listener location alters these resonances).
Many online room mode calculators exist, such as this one (once the calculation is completed, drag your mouse along the frequency chart), however even the addition of a window, or other anomaly throws them off, but they are a good start, though perhaps more suited to an acoustician. For fun, make your room a 10.22' cube and watch the A's fly!
The combination of resonance, reflection or reverberation gives a room its unique acoustic characteristic, and this can be encapsulated in what is called the room's impulse response (IR). IR reverb software plays dry sound through these impulse responses and the end result is akin to having the sound played in the room itself.

Alvin Lucier: I am Sitting in a Room (1969)
The audio portion of this epic audiovisual piece by Mary and Alvin Lucier was made by playing back and rerecording Alvin's voice again and again in a room, until 45 minutes later, with dozens of such generations of playback/rerecord, the speech is completely unintelligible, and the room's natural resonant frequencies completely dominate the texture. Mary Lucier created a series of sequentially degraded Polaroids using a similar recursive process for the visual element of the piece. Listen to it on Youtube.
Text: "I am sitting in a room different from the one you are in now. I am recording the sound of my speaking voice, and I am going to play it back into the room again and again, until the resonant frequencies of the room reinforce themselves, so that any semblance of my speech, with perhaps the exception of rhythm, is destroyed. What you will hear, then, are the natural resonant frequencies of the room, articulated by speech. I regard this activity not so much as a demonstration of a physical fact, but more as a way to smooth out any irregularities my speech might have."
