Chapter Four: Synthesis

13. Speech Synthesis and the Channel Vocoder
A Mini-lesson on Speech Physiology
Speech physiology, a subject involving phonetics, linguistics, anatomy and many more disciplines is a vast subject, but for a common understanding of electronic and computer speech synthesis and relevant terms used in the section below, a very small subset will be discussed here. If you want to dive more deeply into this, a good starting point is the International Phonetic Alphabet (IPA). In addition, Computer Music by Charles Dodge and Thomas Jerse has an excellent chapter on computer synthesis of speech (7.1) which aided in preparing the material below. For this section, however, the somewhat oversimplified discussion below provides a good starting point for speech synthesis concepts.
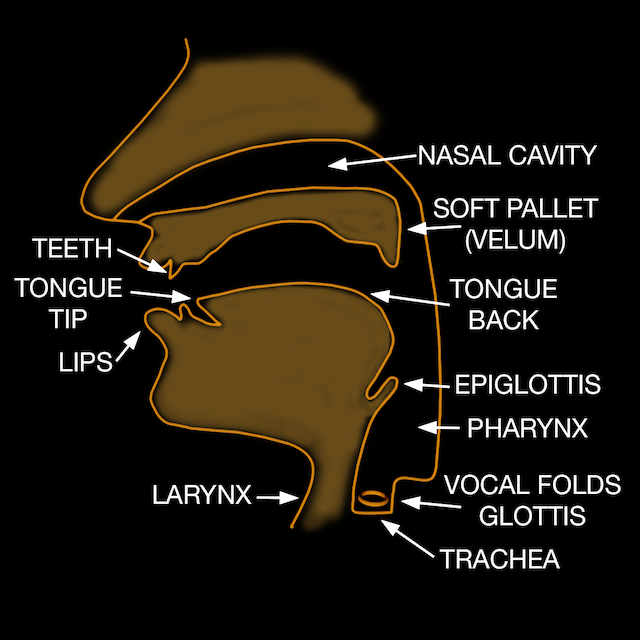
Human Vocal Tract
The human vocal tract consists of the larynx (which includes a triangular opening in the throat called the glottis as well as the vocal folds), pharynx, oral cavity, tongue, vellum (soft pallet), nasal and sinus cavities, teeth and lips.
Two sides of the glottis triangle, pictured left or below, consists of the vocal folds (vocal cords), which are ligament strands separated by gelatinous tissue folds. The glottis can bring those folds together to produce vibrations for so-called voiced sounds, with the folds being excited by expulsion of air from the lungs. It can also snap shut for certain stopped sounds. The pitch of the vibration is controlled by the muscles of the glottis and the tension of the vocal cords. The epiglottis closes the opening to the trachea to route food and liquid down the esophagus (unless you choke).
American English is thought to have approximately 44 distinct sounds, which are referred to as phonemes. Phonemes have been classified broadly into four classes: vowels, diphthongs, semi-vowels and consonants. Consonants can additionally be further sub-classified as being voiced or unvoiced, though they may share the same mouth position. For example, try saying /s/ as in hiss, followed by /z/ as in fizz. Note the /s/ does not engage the vocal cords, but the /z/ does, though they share the same mouth and tongue position.
Voiced sounds include vowels (formants) whereby the particular shape of our oral cavity (including the tongue position) for those vowel timbres remains fixed during production and determines formant frequencies and their relative strengths, much as a multiband filter would. While we are taught in school that a,e,i,o,u and sort of y are the written vowels, there are approximately 11 vowel phonemes. For example /IY/ as in beet or /E/ as in bet, or /AE/ as in hat or /A/ as in mate, exemplify the same written letters producing varied phonemes. The vowel spectrum is produced from the front to back of the mouth along with the shaping and elongation of the lips.
After these simple vowels, most of the other sounds below require some dynamic complexity and combinations of actions to produce. To produce a diphthong, such as /oi/ as in toy, which is an elision of one vowel sound into another, we actively reshape our oral cavity during the phoneme production. There are also a few semivowels (a type of glide) such as /w/ in wet and /y/ as in yes that elide quickly into the vowel they precede and contain no turbulence. As opposed to vowels, they are non-syllabic.
English also has sounds that are both voiced (hence the vocal cords are vibrating) and have a partial obstruction of the vocal tract. These include voiced fricatives such as /v/ as in van, /z/ as in zoo, etc. Fricatives are characterized by additional turbulence cause by constriction somewhere in the vocal tract. There are also unvoiced fricatives where there is no vocal cord vibration–examples are /F/ as in fool, /TH/ as in thought, and a sibilant such as /S/ as in hiss.
Stop consonants can also be voiced or unvoiced, and involve an explosive release of pressure built up by a constricted vocal tract (why we need pop filters on our mics). Hence they are fittingly called plosives. Voiced stops include /b/ as in boy, /d/as in dog, and /g/ as it got. In pronouncing these, note the different spots your vocal tract is closing to produce each. Unvoiced stops include /p/ as in pig and /t/ as in toy. Sometimes the glottis closes completely in what is called a glottal stop. Try saying “uh-oh” but stop halfway through and feel that your glottis has closed to suddenly stop the airflow (now release and breathe...).
Nasals, such a /n/ in noise, are produced by lowering the velum (soft pallet) to route some vibrating air through the nasal cavity to resonate. /M/ as in met or /n/ as in next are examples. Nasals lengthen the vocal tract, and in multiband filter analysis covered later, they are some of the few sounds that have zeros, or aresonance, amongst the poles. Affricatives, such as /tsh/ as in church, begin as a stop and release as a fricative. Finally, a very special sound is the whisper, which has neither voicing or turbulence and whose sole example in English is /h/ as in hat.
Finally, for purposes of economy of means in speech synthesis, rather than stringing stored phonemes together, many speech systems and speech synthesizer chips stored diphones, which are frequently occurring pairs of phonemes. Not only did this save some storage space or processor power, but it also led to a slightly more natural output.

{kind=link}