Chapter Four: Synthesis

13. Speech Synthesis and the Channel Vocoder | Page 6
Follow-on Vocoder and Speech Synthesis Technology
The Dudley human-controlled Voder can be considered an early example of synthesis by rule, since it relied on a pre-learned physical formulas for phoneme succession input by the player, and not by sound analysis. The voder design can also be considered a form of formant synthesis. Formant speech synthesis by rule became widely used in the digital era. Concatenated code for each phoneme or diphone, plus their fundamental pitch, duration and amplitude was used to generate somewhat robotic speech, depending on the sophistication of the software or hardware. It would rarely result in natural-sounding human speech. Charles Dodge used the same digital synthesis by rule technology in his Speech Songs (1972-75), excerpted below, and creatively used both its positive aspects and negative drawbacks. The well-known voice of Stephen Hawking’s custom computer or the HAL 9000 computer singing Daisy Bell (below) in 2001: A Space Odyssey are both examples of early digital formant synthesis by rule.
In 1961, Bells Labs physicists John Larry Kelly, Jr and his Louis Gerstman programmed an IBM 704 computer to synthesize speech, and Kelly and Carol C. Lochbaum synthesized Daisy, using an early vocal tract physical modeling technique, with an accompaniment synthesized by Max Mathews using an early version of his MUSIC language. The following year, Kelly and Lochbaum published an article on the software physical modeling tube-based Kelly-Lochbaum Vocal Tract model, which was highly influential on the later computer-modeled singing voice work of Perry Cook (below) and wave guide synthesis in general.
Speech Synthesis Audio Examples from this page (above and below) |
|
|---|---|
| Example Description | Audio Example |
| Bell Labs Daisy realized by John Kelly and Carol Lochbaum, with an accompaniment synthesized by Max Mathews | |
| Charles Dodge Speech Songs: II He Destroyed Her Image (fragment) | |
| Paul Lansky Six Fantasies on a Poem by Thomas Campion: her song (fragment) | |
| Perry Cook's SPASM Sheila's vocalise over Bell Labs' Daisy Bell (fragment, full version here) | |
| Demo of Mark Barton’s 1982 Software Automated Mouth (S.A.M.) on Apple II computer | |
| Steve Jobs introducing Macintosh in 1984 with MacinTalk text-to-speech descendant of S.A.M. (sort of) | |
Subsequent digital strategies for speech synthesis by analysis that are used musically include the adaptation of linear predictive coding, which uses a frame-based analysis technique similar to FFT’s. Like the later vocoder, LPC analyzes sequential frames of audio input. Each frame of audio is analyzed by an all-pole filter and the resonance levels of the poles for each frame are output as a list of filter coefficients. LPC can also output the predicted fundamental frequency via spectral peaks. Most importantly, the comparison of the filter coefficients from frame to frame generate what is called an error coefficient. While voiced sounds like vowels and diphthongs will produce a more linear succession of each filter pole, unvoiced sounds will be far less linear. The difference generates a value of the deviation from linear succession. The error coefficient value can then be used to switch between voiced and unvoiced resynthesis sources (like buzz and noise). This is substantially more accurate than measuring zero crossings or simply highpass filter levels.
The beauty of LPC is in the resynthesis phase when a single or multiple sound sources can be played through analysis-matching all-pole filters to recreate the characteristic of the input speech when the frame coefficients are fed in at the same rate. OR the playback frame rate can be altered to speed up or slow down from the original. Additionally, the output filter poles can be shifted or re-proportioned in frequency. A classic example of LPC composition is Paul Lansky’s Six Fantasies on a Poem of Thomas Campion (1978), in which his spouse Hannah MacKay spoken voice reading the poem is used to create six unique tableaus, including the polyphonic chorus of the her song movement. While LPC files occasionally suffers from “hot frames” which might contain infinite resonance coefficients, the analysis files were able to be edited. LPC has also been used musically as a form of cross-synthesis, whereby a secondary audio sound source can be piped through the resynthesis filter pole frames as they are played back (one might generate a talking crash cymbal, etc., in this manner).
Aside from implementation in a few remaining programming-type languages such as csound, compositional use of LPC seems to have lost out to other forms of cross-synthesis. Early LPC technology was brilliantly integrated into the 1978 Texas Instrument Speak and Spell toy followed by other early Atari arcade games, where its predictive qualities were actually able to assist in phoneme data reduction. LPC with pitch excitement, called PE-LPC was also the basis for the Apple II's Echo II speech synthesis card, using the TMS 5220 speech chip and is still widely used today in many text-to-speech hardware/software implementations, particularly when economy of means is called for. The early speech synthesizer chips embedded in toys and stuffed animals became great fodder for composer/hackers to rewire and glitch, a type of circuit bending composition.
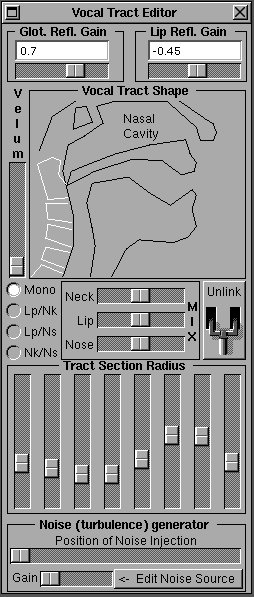
Perry Cook's SPASM
A more modern and effective version of synthesis by rule was the application of physical modeling and wave guide synthesis to speech. Perry Cook’s brilliant SPASM program, which this author used on a NeXT Computer, physically modeled the human vocal tract with important additions to the Kelly-Lochbaum model discussed above. As the graphic shows, the program allowed one to shape the vocal tract through eight sliders, adjust the glottis, adjust the velum and sequence these to produce vocalizations. My favorite music example, linked above, is a tribute Daisy Bell duet between the Bell Labs original and Sheila, the vocalizing SPASM singer. SPASM emanated from Cook's research into singing speech synthesis via vocal tract modeling, with his dissertation available here. Additional musical examples can be found on Perry's SPASM page.
Granular synthesis techniques were also used in artificial speech and vocal production. Two techniques, VOSIM and FOF use pitch-synchronous granular synthesis. Xavier Rodet’s IRCAM-developed CHANT system used the fonctions d’onde formantique (FOF) technique of triggering multiple digital oscillators tuned to formants in short bursts at the beginning of each fundamental pitch period, which are further modified and attenuated by the impulse response of each FOF element. The programmer specifies the center frequency, bandwidth and intensity for each of the formants desired. For voiced sounds, this author, using the csound FOF implementation, was able to take the list of vowel formants, with center frequency, amplitude and bandwidth information, and smoothly glide the FOF note between them.
VOSIM, or Voice SIMulation, was developed at the Institute of Sonology in Utrect and also uses granular spaced pulse special waveforms. Each formant required its own VOSIM oscillator.
Modern corporate techniques developed for digital assistants and computer text-to-speech (TTS), such as SIRI, Alexa and Google Assistant are constantly evolving through machine deep learning. They have come a long was since Mark Barton’s 1982 Software Automated Mouth or S.A.M. was adopted as the voice of the Apple II, 8-bit Atari and Commodore 64 computers, and later developed into MacinTalk (rebranded as Plaintalk for the early Macintoshes). However, most TTS now incorporates a combination of recorded humans (with an accent and language of your choosing) and highly sophisticated artificial speech synthesis. These are referred to as unit selection, whereby natural recorded speech is stored in phonemes and partial phonemes, and reconstructed and concatenated through sophisticated statistical algorithms, and parametric synthesis, which we have just covered as a type of synthesis by rule. Apple and others use this hybrid approach, coupled with deep learning processes to tailor their speech system to the needs of each device. A detailed article about their approach with audio examples of Apple's improvements from OS to OS may be found here. Google DeepMind has also developed a deep learning text-to-speech technology called WaveNet that holds great promise for the future (for deep fakes as well, since it can learn from and synthesize very convincing new speech from analysis of a particular person’s voice). WaveNet is available as an API and Node JS--there are even websites where the WaveNet API will read back your entered text in your chosen celebrity's voice. Welcome to the Uncanny Valley.
